
What Multi Agent Systems Taught Me That Isolated Agents Didn’t
What surprised me was how badly that experience translated once multiple coding agents had to collaborate.

Lately, I have been thinking about a lesson that took me longer to see than it should have.
Not because the signals were weak, but because I had already seen enough success with AI agents in production to believe I was building on solid ground. I had integrated isolated agents into real systems, wrapped them with automated checks, and learned where they needed constraints, evals, and human review to stay useful. But that earlier work was mostly about agents operating inside systems or as isolated workflows. The lesson I am writing about here came from a different kind of setup, using multiple coding agents together to build and evolve a product in a production grade workflow.
That difference turned out to matter a lot more than I expected.
When I started moving from isolated agent workflows into collaborative multi agent systems for development work, I assumed the transition would mostly be about scale. More agents, more orchestration, maybe a stronger knowledge layer, and better routing. What I eventually learned was that the problem had changed. What worked for isolated agents became too restrictive, too wasteful, and in some cases simply the wrong operating model once multiple agents had to collaborate across production work.
If you are short on time, here is the TL;DR.
TL;DR
I had already seen isolated AI agents work in production, with automated pipelines and eval style checks around them. and that experience helped, but it did not automatically prepare me for collaborative multi agent design.
This lesson came from multi agent coding workflows used to build a product, not from agents serving users inside a product runtime.
Direct requirement to agent execution failed because business requirements written for humans were still too ambiguous for agents.
A retrievable knowledge base improved things, but once multiple agents had to collaborate, the system became too heavy, too instruction driven, and harder to coordinate cleanly.
The deeper issue was not just knowledge access. It was coordination, role boundaries, shared versus local truth, synchronization, and explicit collaboration design.
What worked better was a more deliberate operating model built around narrower shared artifacts, clearer contracts, scoped agent responsibilities, evals, and human intervention where ambiguity had real cost.
What I was actually trying to solve
This was never an AI for AI’s sake exercise. The real problem was much more practical. How do you move quickly enough to ship in a fast market while keeping the system healthy enough to survive real change?
That balance matters. Speed matters because delivery matters. You rarely get the luxury of solving every edge case before release, and older quality models do not always transfer cleanly into modern AI assisted development. At the same time, architecture, code quality, performance, security, maintainability, and evaluation still matter enough that if you neglect them, you eventually slow yourself down harder than if you had been more deliberate from the start.
So the job was never to choose between speed and engineering discipline. It was to find the operating middle ground. AI agents simply made that problem more visible.
Why I thought I was better prepared than I actually was
I had real reasons to feel confident going in. I had already worked with agents inside production systems. I had already seen the value of automated evaluation pipelines. I had already learned that agents perform well when tasks are scoped properly, tools are explicit, and verification is part of the workflow instead of an afterthought.
That experience taught me a lot. It taught me how to constrain tasks, how to separate generation from verification, and how to spot obvious failure modes before they became operational problems.
What it did not teach me well enough was how collaboration changes the shape of the problem.
Isolated agent success mostly teaches you how to define a task, give an agent the right tools, and judge its output. Collaborative systems introduce a different class of engineering concerns, role boundaries, evolving shared context, synchronization points, ownership of truth, and the cost of letting multiple agents operate over the same moving system. That becomes even sharper when the agents are not serving the product directly, but are part of the delivery system that builds it.
That was the trap. My prior experience was real, useful, and earned. It just solved a narrower problem than the one I was now facing.
The first approach failed for a very predictable reason
My first instinct was the obvious one, direct requirement to agent execution.
Give the agent the requirement, add enough surrounding context, let it plan, let it implement, then let review and test workflows catch whatever slips through. On paper, that sounds efficient. In practice, it fails as soon as the requirement depends on too much implied intent.
The issue was not that business requirements were unimportant. The issue was that business requirements written for humans are often too ambiguous for agents unless they are turned into more precise, scoped, agent friendly truth. Humans can recover missing intent from prior conversations, domain knowledge, and product context. Agents are much less reliable at doing that safely.
That was the first failure mode. The system was still leaning too heavily on human readable intent.
The second approach fixed one problem and created another
The natural response was to make the truth more explicit. So I introduced a knowledge base that agents could retrieve from selectively using MCP. I made feature level information more structured. I tightened the guidance around what needed to be consulted before certain kinds of work.
This helped immediately. Drift reduced. Constraints became clearer. Repeated decisions stopped living only in my head. Agents had stronger grounding, and certain classes of mistakes became less frequent.
But as soon as multiple agents started interacting across backend, frontend, review, testing, performance, security, and documentation flows, the limits of that approach started to show.
The knowledge layer began solving the wrong problem too aggressively. Shared documentation was no longer just a stabilizer. In some cases it became drag. Some agents were reading more than they needed and wasted too much token. Some instructions were visible to everyone even though they only mattered to one role. Some truths needed to be shared, while others should have remained local. The system was getting stronger in one direction and clumsier in another.
That was the second lesson. More structure is not automatically better structure, especially when multiple agents have to coordinate instead of simply execute.

Fig 1: How the operating model matured, from direct execution to scoped collaboration.
The real issue was not knowledge access
The deeper problem was coordination.
Once I looked at it that way, the symptoms made more sense. A backend implementation agent, a frontend agent, a review agent, a testing agent, a performance agent, a security agent, and a documentation agent should not all consume the same truth in the same way. Some knowledge has to be shared. Some should stay local to a role. Some should move through contracts. Some should only be pulled in when a task crosses a boundary such as RBAC, mobile versus web behavior, or data exposure.
Until that became explicit, the system kept paying the price in the same places, duplicated interpretation, stale assumptions, unnecessary retrieval, and fuzzy ownership of what each agent was actually supposed to know.
That was the turning point for me. The question stopped being how much context should I give the agent, and became what truth should this agent have, what should it never need to read, and where should synchronization happen instead of assumption.
That is a much more useful question.
It also lines up with how the major labs describe serious agent systems today. Anthropic frames agent work as a loop of gathering context, taking action, and verifying the result, with file and folder structure itself becoming part of context engineering. OpenAI’s guidance makes a similar point, clear instructions, clear tools, and orchestration patterns need to match the real complexity of the workflow instead of assuming one agent pattern scales everywhere.
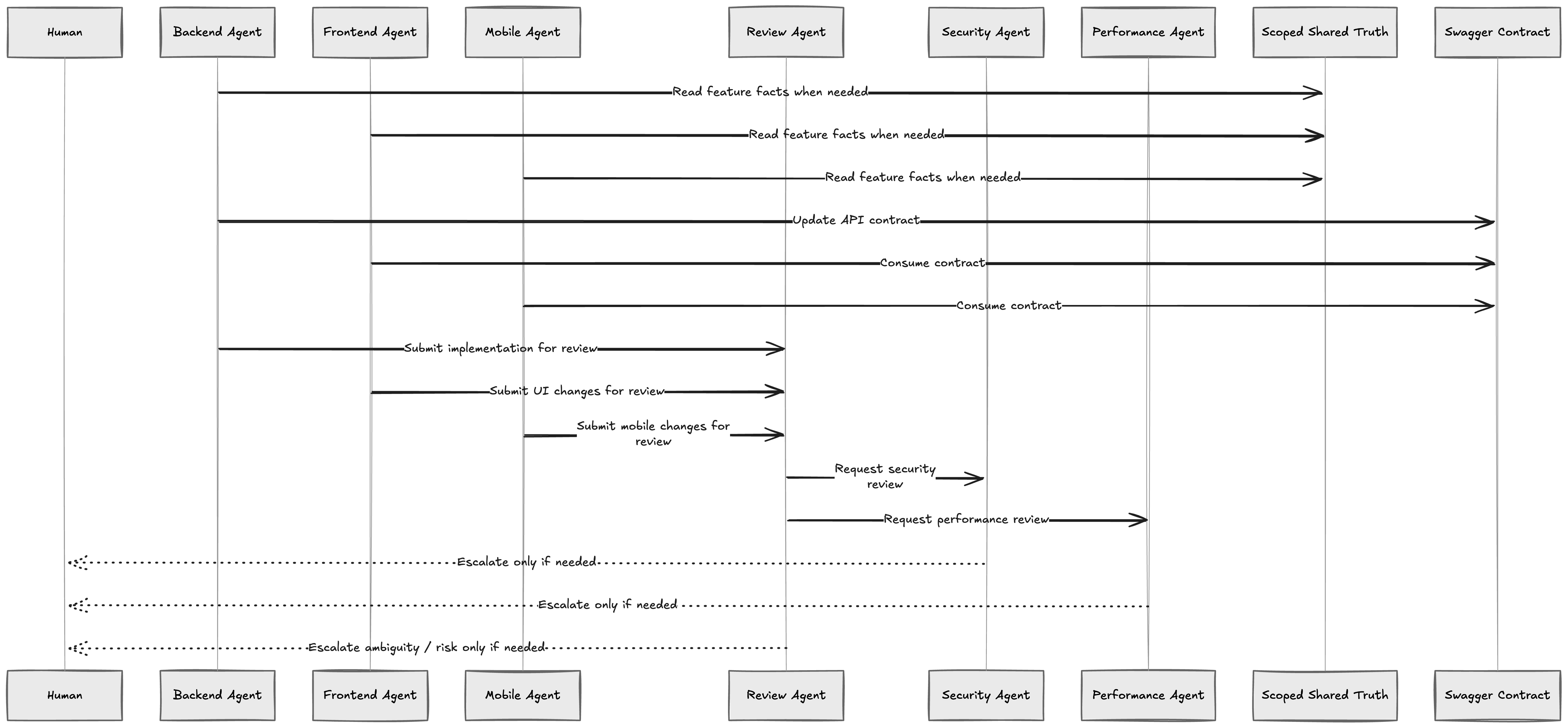
Fig 2: A simplified view of the multi-agent collaboration model, showing how shared feature truth, API contracts, specialist review agents, and human escalation points work together during delivery.
What changed after that
The system improved when I stopped trying to make all agents broadly informed and started making them selectively aligned.
Feature truth became smaller and more scoped. Test obligations became explicit without turning into giant shared checklists. Stable contracts, especially around APIs, became more important. Some information stayed local to the role that needed it. Shared information was reduced to what multiple agents genuinely had to agree on.
That changed the collaboration model in a useful way. Backend agents no longer had to over explain themselves to frontend or mobile agents because a stable contract could carry that responsibility. Review oriented agents no longer needed broad product context to judge narrower concerns. Security and performance checks became easier to target because their scope was clearer. The shared documentation layer stopped behaving like a giant memory pool and started behaving more like a coordination surface.
That was the real breakthrough. Not better prompts. Not more documentation. Better collaboration design.
Why I didn’t stop at documentation
Even after the structure improved, one thing stayed true. Documentation is guidance, not proof.
So I started evaluating the workflow, not only the final output. I checked what the agent read, whether it stayed inside the right role boundary, whether it preserved hard denies, whether it asked when a rule or contract was unclear, and whether it ran only the checks that matched the actual change.
In Claude Code, hooks made this much easier. I used them to surface drift early, flag policy violations, and show what the agent touched so I did not have to inspect everything manually. I did not use them to over-control the workflow. I used them to make the workflow visible and to stop only when it crossed the boundaries that mattered.
In Codex, I handled this differently because I could not rely on the same hook model. So I made the agents explain themselves. They had to report what they consulted, what they changed, what they did not change, and why. That gave me a small review summary that I could inspect quickly without reading the whole session again.
Human input stayed in the loop, but only where it mattered. I did not want humans approving every small step. I wanted escalation only when the agent hit RBAC changes, contract uncertainty, privacy-sensitive outputs, regulated commands, or anything else that could cause real drift.
That made the system much more practical. The documents guided the work, the evals checked the workflow, and the human stepped in only when the risk was worth the interruption.
What this changed for me as an engineer
The biggest change for me is where I now see the leverage.
It is still important to write good code, reason about systems, and make sound technical decisions. But once agents become part of the delivery system, you cannot review everything with the same depth, in the same way, at the same speed as before. Delivery moves faster, output volume increases, and the real job becomes making sure that speed does not quietly weaken the system.
That changed my focus. Instead of trying to inspect everything equally, I put more effort into defining strong boundaries, clearer rules, and better review paths. That is where sub-agents became genuinely useful. Narrower agents could review security, performance, correctness, and scope alignment much faster, while human attention stayed focused on ambiguity, architectural impact, and the places where mistakes would actually be expensive.
That changed the economics of delivery for me. Spending an extra minute or two to verify that a change is aligned and structurally sound is far cheaper than spending days cleaning up drift later. So the leverage moved. It is not only in writing the change, but in designing the system that helps changes land quickly without weakening everything around them.
Where I think people should actually start
If I were advising someone building a collaborative multi agent setup today, I would not tell them to start with a giant shared knowledge base. I also would not tell them to start with elaborate prompt stacks and assume the rest will follow.
I would tell them to start with boundaries.
Decide what knowledge is local to a role and what knowledge is genuinely shared. Decide what should move through stable contracts. Decide where humans must intervene. Decide what your evals need to verify beyond output correctness. Decide what must never be inferred.
That is the actual design work.
The hardest part of collaborative multi agent systems is not making agents more informed. It is making them collaborate without stepping on each other’s assumptions.
That was the lesson I had to learn the hard way, and it is the one I would start with now.